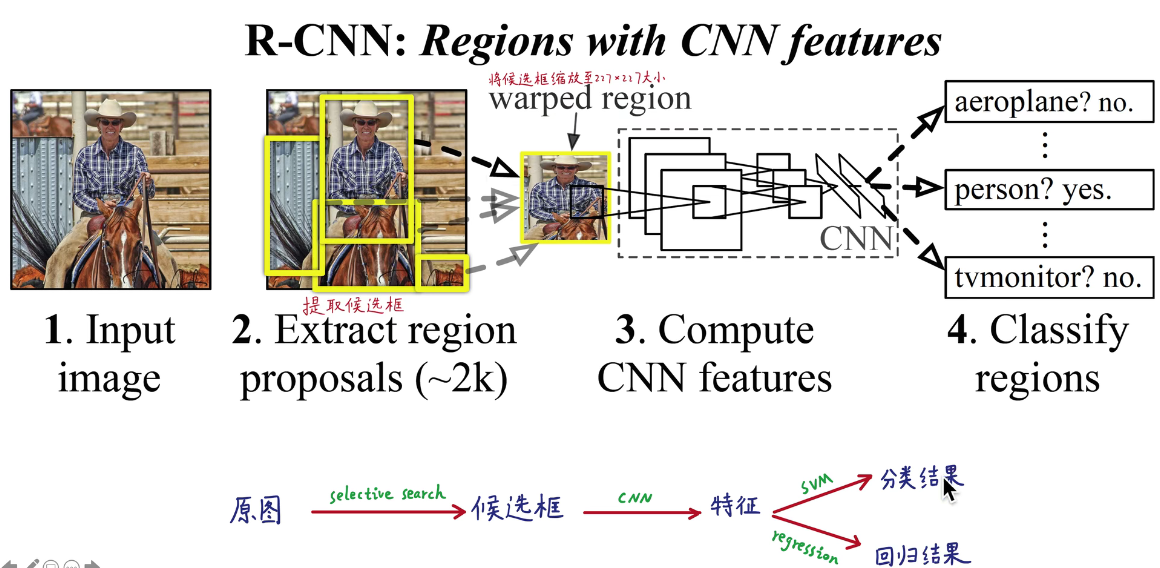
★★★基本原理
- 输入图像
- selective search生成2000个候选框
selective search——产生候选框
类似于聚类的方法,先找到一些区域,再多次进行加权合并,2000个框里基本总有框会和目标框大概一样
- 缩放成227*227,逐一喂到神经网络,全连接得到4096维的特征
缩放
- 非等比例缩放,连带邻近像素(本文,连带像素p=16)
连带像素、扩充:Dilate proposal
- 等比例缩放,连带邻近像素
- 等比例缩放,不连带邻近像素
- 非等比例缩放,不连带邻近像素
- 4096维特征用线性SVM分类/回归
摘要
mAP指标提升了30%,两个贡献,分别是提出高表示能力的卷积神经网络和在大数据集上训练再迁移(用于目标检测的数据集太小)。
Intro
特征很重要。像素特征属于低级特征,没有抽象成语义特征,所以有潜力。
ふくしま,1979,神经认知机,仿生模型,分层的,Lecun将其演进。
90年代CNN挺火,后来被SVM抢了风头,后来被AlexNet拉回来了。
目标检测与图像分类的不同,要定位和分类。把目标检测问题当成回归问题来解决很困难。滑动窗口方法要求高分辨率,卷积只能很浅。
后来的YOLO是当成回归问题了。
我们使用卷积神经网络来定位,采用两阶段范式。
(基本原理部分)
传统方法使用无监督预训练,再监督微调。本文使用监督预训练,在大规模数据集上,再在小规模数据上微调,微调提成了八个百分点,mAP达到了54%。
R-CNN很高效。
其实不算高效。为赋新词强说愁!
加入回归,可以微调候选框,使得定位更加精确。
R-CNN用于目标检测
模型设计
提取候选框
selective search:聚类产生初始分割区城,根据颜色、纹理、大小、形状、相似度加权合并产生不同层次的2000个候选。
大部分候选框没啥用,无用的计算,浪费了。
候选框特征提取
缩放成227*227的RGB,然后减去平均值。非等比例缩放,连带邻近像素p=16。送入卷积神经网络得到3096维向量特征。
检测
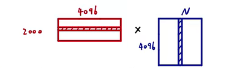
53s一张图。所有类别共享一套特征。
如图所示,第一个矩阵为2000个候选框的特征,第二个为SVM权重矩阵(N:类别数),两个矩阵相乘得到某个候选框在某个类别的概率。这个分类还是很高效的。
训练
先在ILSVRC分类数据集上预训练,简化了训练模型所以性能差两个百分点,载迁移学习微调。把IoU>=0.5的正样本进行训练。
训练SVM分类器。
最后一层不直接用全连接层而是用SVM。
结果
跟UVA相比(都用了selective search):UVA用了四阶段的金字塔模型,像素层面的传统计算机视觉方法。
在VOC2010测试集上成绩很好。
可视化、消融和误差模式
可视化
卷积神经网络中,第一层勉强还能看个轮廓,再往后就很难观察了。
本文挑选一个特征出来,把它直接当成一个物体分类器,然后计算它们处理不同的候选区域时,activation 的值,这个值代表了特征对这块区域的响应情况,然后将 activation 作为分数排名,取前几位,然后显示这些候选区域,自然也可以清楚明白,这个 feature 大概是什么。
将 pool5 作为可视化对象。
消融精简
发现 fc7 的意义没有 fc6 大,甚至移除它之后,对于 mAP 结果指标没有影响,还减少将近 1800 万个参数。
同时移除 fc6 和 fc7 并没有多大的损失,甚至结果还要好一点点。
神经网络最神奇的力量来自卷积层,而不是全连接层。
目标检测错误分析
R-CNN 作者采用了 Hoiem 提出的目标检测分析工具,能够直观地揭露错误的模型,作者通过这个工具针对性地进行 fine-tune。
bbox 回归
bbox 的值其实就是物体方框的位置,预测它就是回归问题,而不是分类问题。
训练了一个线性的回归模型,这个模型能够针对候选区域的 pool5 数据预测一个新的 box 位置。
还可以做语义分割
(没看了)
改进R-CNN
- 提取候选框∶ Edge Boxes、RPN网络
- 共享卷积运算:SPPNet、Fast R-CNN
- 兼容任意尺寸图像:SPP、ROI Pooling
- 预设长宽比:Anchor
- 网络结构:端到端
- 融合各层特征:FPN