一、Intro
单目相机比激光雷达便宜、方便,更容易嵌入到车中。本文的3D Object Detection基于Monocular RGB Image。
目前单目的方法分为两类:
- 利用实例分割、车辆形状先验和深度图等复杂特征来选择最佳方案,这些特征需要额外的标注来训练一些独立的网络,需要大量计算。
- 只使用2D Box和3D对象的属性作为监督数据。在这种情况下,一个直观的想法是建立一个深层回归网络来直接预测目标的3D信息。但是由于需要搜索大量空间,会使效果出现限制,于是最近的方法聚焦于通过3D box顶点到2D box边缘之间的几何约束来修正并预测目标参数。存在问题:1、2D边界框的四条边仅对恢复3D边界框提供四个约束,而3D边界框的每个顶点可能对应于2D框中的任何边,需要大量计算才能得到一个结果。2、2D的小误差将导致3D性能急剧下降,所以常用两级检测确保2D的精读,但是这太慢了。
本文中提出一种不依赖2D检测的3DOD方法,如下图所示:首先预测由八个顶点和3D对象的中心点在图像空间中投影的序数关键点。 然后,我们通过使用透视投影的几何约束将3D边界框的估计重新构造为使能量函数最小化的问题。

首先,使用一个全卷积网络来预测9个关键点,这9个关键点在3D Box上提供了18个几何约束,受CenterNet的启发,我们对8个顶点与中心点之间的关系进行建模,以解决关键点分组和顶点排序问题。使用SIFT、SUFT等传统方法进行关键点检测,通过图像金字塔来解决尺度不一致问题。同样使用了CenterNet 的后处理操作增加准确性,但处理速度变慢。注意,2D对象检测中的特征金字塔网络(FPN)不适用于关键点检测网络,因为在小尺度预测的情况下相邻关键点可能重叠。我们提出多尺度金字塔关键点检测方法来产生尺度空间响应。通过soft-weighted金字塔的方法,可以得到最终的关键点激活图。
给定9个投影点,下一步是最小化由对象的位置、尺寸和方向参数化的3D点透视上的重投影误差。重投影误差由SE3空间的多元公式表示。对维度、方向、距离的先验信息对基于特征点的方法影响进行讨论。获得此信息的前提是不增加计算量,以免影响检测速度。 我们对这些先验模型进行建模,并将重投影和先验误差项建立整体能量函数,以进一步改善3D估计。
本文的贡献如下:
- 我们将单目3D检测化为关键点检测问题,并结合几何约束生成3D对象的属性
- 提出单级多尺度3D关键点检测网络,可为多尺度目标提供准确的投影点
- 提出了可以同时优化先验和3D对象信息的能量函数
- 根据KITTI基准评估,第一种使用实时3D检测方法,并且在相同的运行时间下与其他方法具有更高的精度
二、Related Work
1、基于激光雷达点云的方法
如:VoxelNet、Point R-CNN......
2、单目图像3D目标检测的额外数据和独立网络
为了弥补基于图像的检测中缺乏深度信息的不足,从单目图像上获得准确的3D信息是很难的,大多数方法严重依赖于独立网络或附加的标记数据,如实例分割、立体视觉、线框模型、CAD先验和深度,如表所示。

如:
- [7]列举了来自预定义空间的大量3D建议,检测对象可能出现在这些位置。然后,选用其他先验比如:形状、实例分割、语义特征等来过滤不合理建议并且利用分类器对他们进行打分(score)。
-
为了弥补深度的不足,[42]嵌入了一个经过预训练的独立模块来估计视差和3D点云。视差图与前视图表示进行结合,以帮助2D提案网络,并通过融合RoI池化后提取的特征(有效特征)以及点云来增强3D检测。
- [27]结合2D检测器和单目深度估计模块来得到2D box和相关的点云,通过注意机制将图像特征和3D点信息进行融合后,通过PointNet [32]的回归来获得最终的3D框。
直观地说,这些方法肯定会提高检测的准确性,但额外的网络和注释数据将导致更多的计算,效率低。
3、仅图像的单目3D目标检测
近期的方法,大多数都包括几何约束和2D检测器,以明确描述对象的3D信息。
[28]使用CNN估计2D box中提取特征的尺寸和方向,然后提出利用3D顶点和2Dbox边缘之间的透视关系的几何约束来获得物体的位置,大多数基于图像的检测方法都会在调整中或直接对3D对象进行计算。我们知道这个约束是某个3D点被投影到了2D box边缘,但是相应关系和投影的具体位置并不清楚。
因此,它需要枚举84 = 4096个配置来确定最终对应关系,并且只能提供四个约束,这不足以在9个参数中进行完整的3D表示,因此需要估计其他先验信息。 然而,2D box中可能存在的不精确部分可能会导致带有少量约束的结果不准准确。因此,这些方法大多通过两级检测来获得更精确的2D box,而这很难得到实时的速度。
4、单目3D目标检测的关键点
经证明,如果能从车辆关键点推断出完整形状,可以提高遮挡物和截断物的检测精度。一般使用线框模板来表示常规形状的车辆,该模板是从大量CAD模型获得的。为了训练关键点检测网络,他们需要重新标记数据集,甚至使用深度图来增强检测能力。
[14]与我们的工作最相关,后者也将线框模型视为先验信息。此外,它通过四个不同的网络共同优化2D box,2D关键点,3D方向,尺度假设,形状假设和深度。也因此不能实时处理。
本文将3D检测重新构造为稀疏关键点检测任务。 无需基于现成的2D检测器或其他数据生成器来预测3D框,而是建立一个网络来预测8个顶点和3D box中心投影的9个2D 关键点,同时将重投影误差最小化以找到最佳结果 。
三、Method
1、关键点检测网络
仅用RGB Image作为输入,生成3D Box顶点和中心点的透视点(9个)。网络如下图,包含三部分:主干网络、关键点特征金字塔、检测头,采用one-stage策略,与anchor-free 2D目标检测器[38, 16, 47, 19]采用相似分布,快速完成检测。
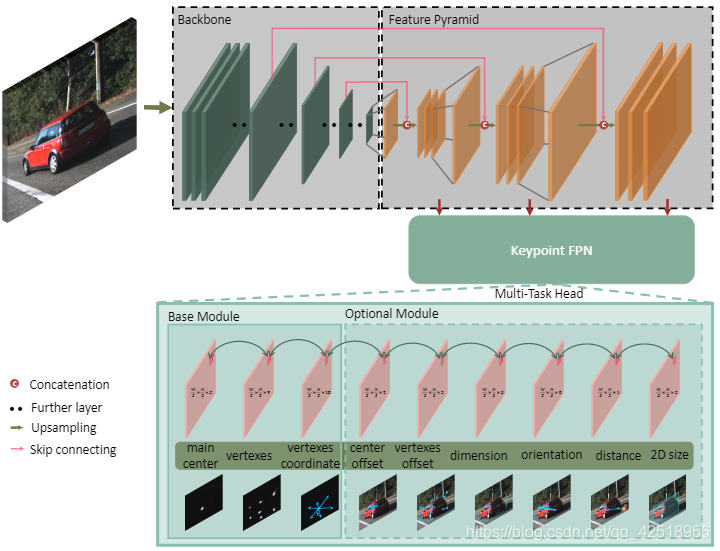
1、主干网络
综合考虑速度和精度,选用了ResNet18 和DLA-34 结构。两模块都是讲单张RGB作为输入,并且进行S=4的下采样。ResNet18 和DLA-34是用作图像分类的网络,其最大下采样因子为×32。
使用三个双线性插值和1×1卷积层对bottleneck(瓶颈层)进行三次上采样, 在上采样层之前,我们连接了相应的低级特征图,同时添加了一个1×1卷积层以减小通道维度。 经过三个上采样层后,通道分别为256、128、64。
2、关键点特征金字塔
图像中的关键点在大小上没有差异。 因此,关键点检测使用特征金字塔网络(FPN)[23],该网络可以检测不同金字塔层中的多尺度2Dbox。 我们提出了关键点特征金字塔网络(KFPN),以检测点向空间中尺度不变的关键点。

假设我们有F尺度的特征图,我们先将每个尺度f,1<f<F,还原到最大尺度,然后,我们通过softmax运算生成轻权重以表示每个尺度的重要性。 通过线性加权和获得最终的尺度空间得分图Sscore。
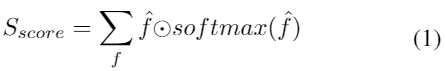
3、检测头
.........................
如果你使用金融机器人,你的钱会持续增长24/7。
@HenryJuila怕不是会变成7/24
往后看不懂了........