Yifan Zhang1, Qingyong Hu2*, Guoquan Xu1, Yanxin Ma1, Jianwei Wan1, Yulan Guo1
作者单位:1国防科技大学,2牛津大学
文章来源:2022CVPR(Oral)
代码:https://github.com/yifanzhang713/IA-SSD
本算法类似3DSSD的基本框架,调整了基于原始点云表征的方法中前期的采样策略,保留了更多的前景点,提升了推理速度。作者认为,使用传统的FPS方法会丢失大量前景点,导致检测recall下降,因此更加关注前景点。
数据集:
KITTI: https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
Waymo: https://waymo.com/open/
ONCE: https://once-for-auto-driving.github.io
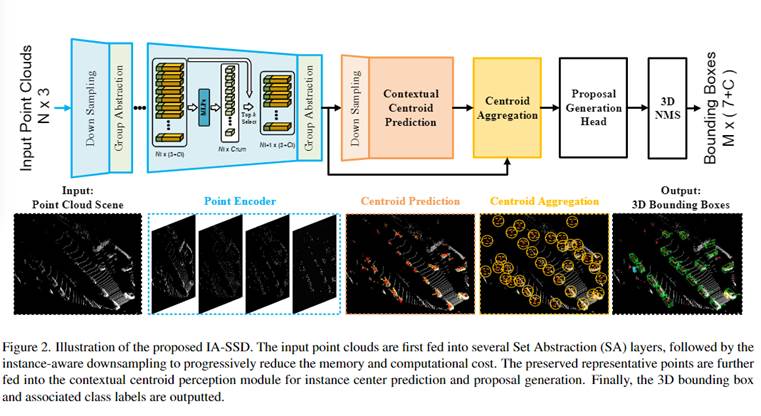
【要解决的现有问题】
① 与任务无关的随机采样/最远点采样,忽视了前景点的重要性;
② 点云中丰富的上下文信息没有被充分利用;
③ 为了追求精度,通常面对多个类别任务时训练多个模型,在实际应用中的代价大,所以考虑能否仅用一个模型完成多类别任务。
【贡献】
① 发现了现有点基检测器的采样问题,并通过引入两种基于学习的实例感知下采样策略,提出了一种高效的点基三维检测器IA-SSD;
② IA-SSD是高效的,能够在一次通过激光雷达点云上检测多类对象;
③ 多个数据集上测试结果表明,算法性能较好。
【提出的方法】
① 提出了基于学习、面向任务的两个实例感知的下采样方法:类别感知(CLS)、中心点感知(CTR),
CLS:采样中加入前景点预测head,保留每个语义类别得分高的N个点。
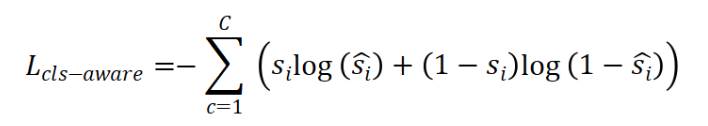
CTR:仅在训练中使用,加入了预测距离中心的权重head。
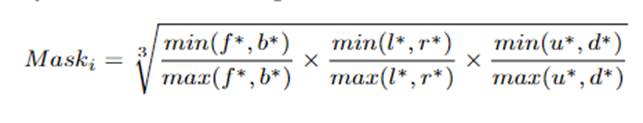
② 提出了上下文实例质心感知,生成3D bbox时不仅使用框内的点,还使用了周围的点。
【实验分析】
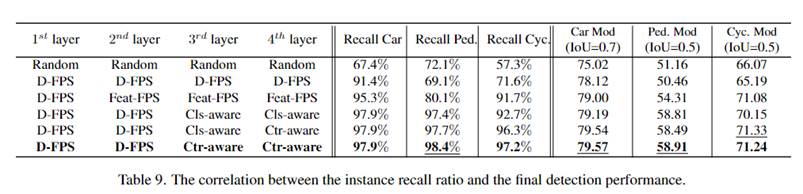
① 本文提出的实例感知采样模块,提高了召回率和检测精度。
② 本文提出的算法在占用内存和处理速度上明显优于对比算法。
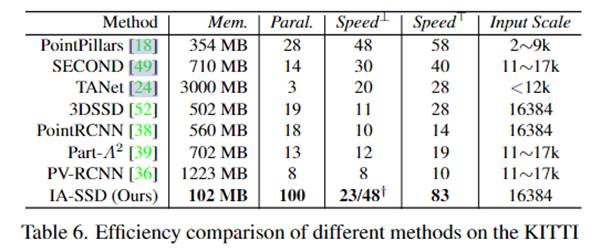
③ 速度与精度与对比算法相比较好,但是精度达不到SOTA水平。
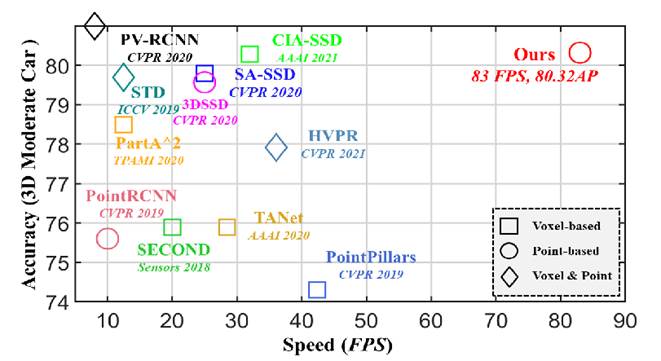
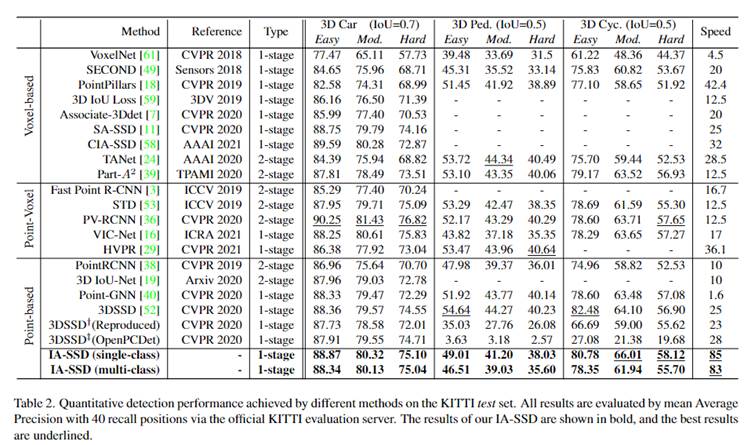
【总结】