Intro
大数据集,训练一个大模型,使用了GPU(GTX580*2)。
5个卷积层,3个全连接层,深度很重要。
数据集
ImageNet:ImageNet (image-net.org)
首先重新缩放图像,使短边的长度为256,裁剪成256*256的图片。
结构
ReLU
使用ReLUs进行深度卷积神经网络训练的速度比使用tanh训练的速度快几倍。
GPU*2并行计算
没办法的操作,当时一块GPU带不动。
LRN
采用LRN局部响应正则化可以提高模型的泛化能力。
重叠池化
传统池化时卷积核提取的每一小块特征不会发生重合,譬如kernel size记为z×z,步长stride记为s,当z = s时,就不会发生重合,当z > s时,就会发生重合,即重叠池化。AlexNet训练中的stride为2,kernel size为z = 3,使用的就是重叠池化。
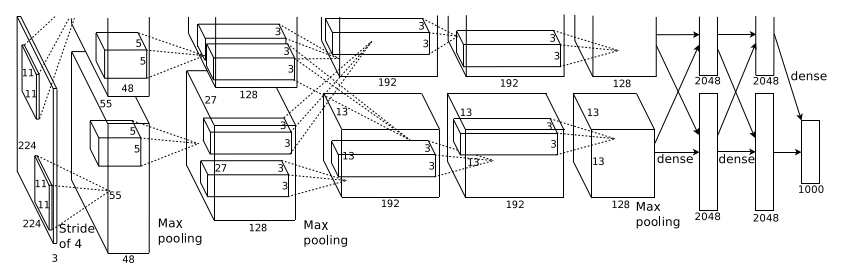
总体架构
整个AlexNet网络共12层,包括输入层×1、卷积层×5、池化层×3、全连接层×3,示意图中隐藏了池化层。
图中保留了GPU0的下半部分和完整的GPU1的全部,给GPU0切掉了一半就很无语。
降低过拟合
过拟合:也称为过学习,它的直观表现是算法在训练集上表现好,但在测试集上表现不好,泛化性能差。过拟合是在模型参数拟合过程中由于训练数据包含抽样误差,在训练时复杂的模型将抽样误差也进行了拟合导致的。所谓抽样误差,是指抽样得到的样本集和整体数据集之间的偏差。
本文的两种方法
- 生成图像平移和水平反射
- 改变了训练图像中RGB通道的强度
Dropout
训练采用了0.5丢弃率的传统Dropout。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
训练
随机梯度下降!
所有层采用了相同的初始化为0.01的学习率,不过可以手动调整。
weight deay对模型的学习很重要。
结果
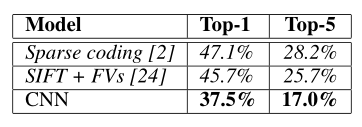
讨论
一个大型的、深度的卷积神经网络能够在一个高度挑战的数据集上使用纯监督学习获得破纪录的结果。如果去掉AlexNet网络中的任意个卷积层,整体性能就会下降约2%,可见,网络的深度很重要。