预定义边框就是一组预设的边框。
BEV——鸟瞰图
ΔwΔh)对应离散化后的图像的一个像素点(或一组特征向量),如点云20cm20cmΔh的长方体空间,对应离散化后的图像的一个像素点。
Down Sampling——下采样
缩小图像,类似于池化,相反还有上采样。
对于一幅图像I尺寸为MxN,对其进行s倍下采样,即得到(M/s)x(N/s)尺寸的得分辨率图像,当然s应该是M和N的公约数才行,如果考虑的是矩阵形式的图像,就是把原始图像sxs窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值。
上采样
图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
Feature Alignment——特征对齐
FPN——特征金字塔
FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。
高层特征上采样后可以和低层特征融合。
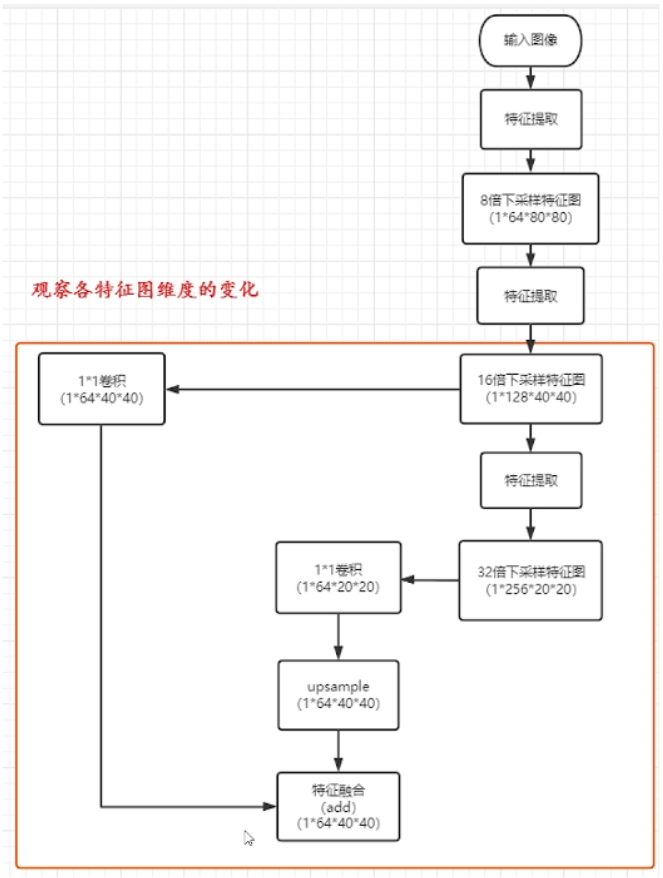
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而FPN不一样的地方在于预测是在不同特征层独立进行的。
其他的特征提取方式:
基础CNN
图片金字塔
多尺度特征融合
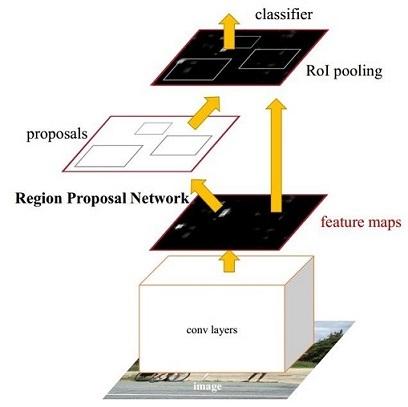
RPN——区域生成网络
Faster R-CNN中提出的一个全卷积网络,用于从图像中提取建议框。
可以认为Faster R-CNN=RPN + Fast R-CNN。
通俗讲是“筛选出可能会有目标的框”。其本质是基于滑窗的无类别object检测器,输入是任意尺度的图像,输出是一系列矩形候选区域。
Faster R-CNN网络图:
Selective Search——选择性搜索
R-CNN中使用了。
首先使用论文“Efficient Graph-Based Image Segmentation”中的方法生成一些起始的小区域,之后使用贪心算法将区域归并到一起:先计算所有临近区域间的相似度(通过颜色,纹理,吻合度,大小等相似度),将最相似的两个区域归并,然后重新计算临近区域间的相似度,归并相似区域直至整幅图像成为一个区域。
SIFT
SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述方式。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
SPP——空间金字塔池化
SPPNet中提出的,一种可以让输入为任意尺寸的方法。
卷积层输入任意尺寸的图像,提取出不同尺寸的特征图,将这些特征图经过空间金字塔池化(区域切割后进行最大值池化)后得到同一尺寸的特征,作为全连接层的输入。
可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
SOTA
SOTA也就是state-of-the-art,若某篇论文能够称为SOTA,就表明其提出的算法(模型)的性能在当前是最优的。
哈哈哈我还以为是个啥呢,整天看见有人提。